Activation Function是將線性迴歸轉換為非線性函數,使神經網路更具通用性(Generalization),類似Kernel PCA及Kernel SVM,這是機器學習將線性模型轉換為非線性函數常用的方法。Activation Function被直譯為『激勵函數』,不能表達真正的意義,故以下介紹直接使用Activation Function。
TensorFlow官網首頁模型建構的程式碼如下:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
其中第1個Dense參數activation='relu',表示完全連接層(Dense)後面連接ReLU Activation Function,也可以寫成:
tf.keras.layers.Dense(128),
tf.keras.layers.ReLU(),
第2個Dense參數activation='relu',表示完全連接層(Dense)後面連接Softmax Activation Function,也可以分兩行撰寫。
神經網路中間的隱藏層常使用ReLU Activation Function,最後一層則會使用Softmax Activation Function,原因如下:
可以參考維基百科Activation Function說明,內文有一列表,部份截圖如下:
欄位包括Activation Function名稱、函數繪圖、公式、一階導數、範圍及連續性。
以sigmoid為例,公式如下: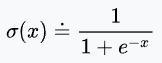
若原來模型是 y = wx + b,經過轉換將x置換為wx + b,公式如下: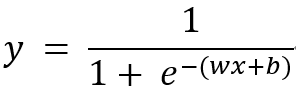
TensorFlow提供更多的Activation Function,可參閱Keras說明或TensorFlow說明。
範例1. 將TensorFlow官網首頁的範例拿掉Activation參數,測試其影響。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
重新訓練,結果準確度只有0.91,少了0.06。
拿掉第2個Dense 的 Activation參數:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
pred = model.predict(x_test[:10], verbose=False)
for i in range(10):
print(f'pred={pred[i]}, max={np.argmax(pred[i])}')


由於Activation Function有非常多種,如果沒有一一試過,很難知道特定訓練資料適合使用哪一種Activation Function,因此,在2024年5月有一篇論文【KAN: Kolmogorov-Arnold Networks】曾引發廣泛的討論,作者試圖直接以貝茲曲線(B-spline curve)取代Activation Function,直接訓練模型,找出控制點最佳值,亦即直接求解非線性函數,但經過一段時間後討論熱度就冷卻下來了,筆者認為神經網路的重點不在Dense,而是其他的神經層,例如卷積層(Convolution),將輸入像素轉換為線條,又如嵌入層(Embedding)將文字轉換為實數向量,RNN考慮上下文(Context),重點在於特徵工程(Feature engineering)。KAN的詳細介紹可參閱筆者撰寫的『Hello KAN, 建構深度學習模型的另一種思維』。
Activation Function也是模型建構重要的一環,通常每個Dense後面都會連接Activation Function,可有效提高模型準確率,千萬不要忽略,下一篇將介紹損失函數,Happy coding。
徹底理解神經網路的核心 -- 梯度下降法 (1)
徹底理解神經網路的核心 -- 梯度下降法 (2)
徹底理解神經網路的核心 -- 梯度下降法 (3)
徹底理解神經網路的核心 -- 梯度下降法 (4)
徹底理解神經網路的核心 -- 梯度下降法的應用 (5)
梯度下降法(6) -- 學習率動態調整
梯度下降法(7) -- 優化器(Optimizer)
梯度下降法(8) -- Activation Function
梯度下降法(9) -- 損失函數
梯度下降法(10) -- 總結
 I code so I am
I code so I am
